25赫兹相敏轨道电路故障智能诊断方法(人工智能期末作业)
# 背景简介
轨道交通是一种安全、高效、节能、舒适并可持续发展的交通运输方式,在世界各国受到广泛重视。当前,我国是世界上轨道交通发展速度最快、系统技术最全、集成能力最强、运营里程最长和在建规模最大的国家。
轨道交通行业快速发展,对轨道交通信号设备的安全性和可靠性的要求越来越高。25赫兹相敏轨道电路是重要的轨道交通信号设备,其一旦出现故障,轻则影响行车效率,重则造成车毁人亡。目前,轨道交通运营管理部门主要采用人工巡检、信号集中监测等措施实现无绝缘轨道电路的故障诊断。这些以人工判断为主的故障诊断方法已不能满足当前我国轨道交通行业快速发展的需要。如何实现无绝缘轨道电路故障诊断的智能化,已然成为限制轨道交通系统健康、快速发展的瓶颈之一。
25Hz相敏轨道电路是一种相对来说组成比较简单的轨道电路。总体上,其主要可以分为两个部分:室外部分和室内部分,同时又可以细化为送电端与受电端。具体构成如表1所示:

25Hz相敏轨道电路在分路状态下的工作原理示意图如图1所示。
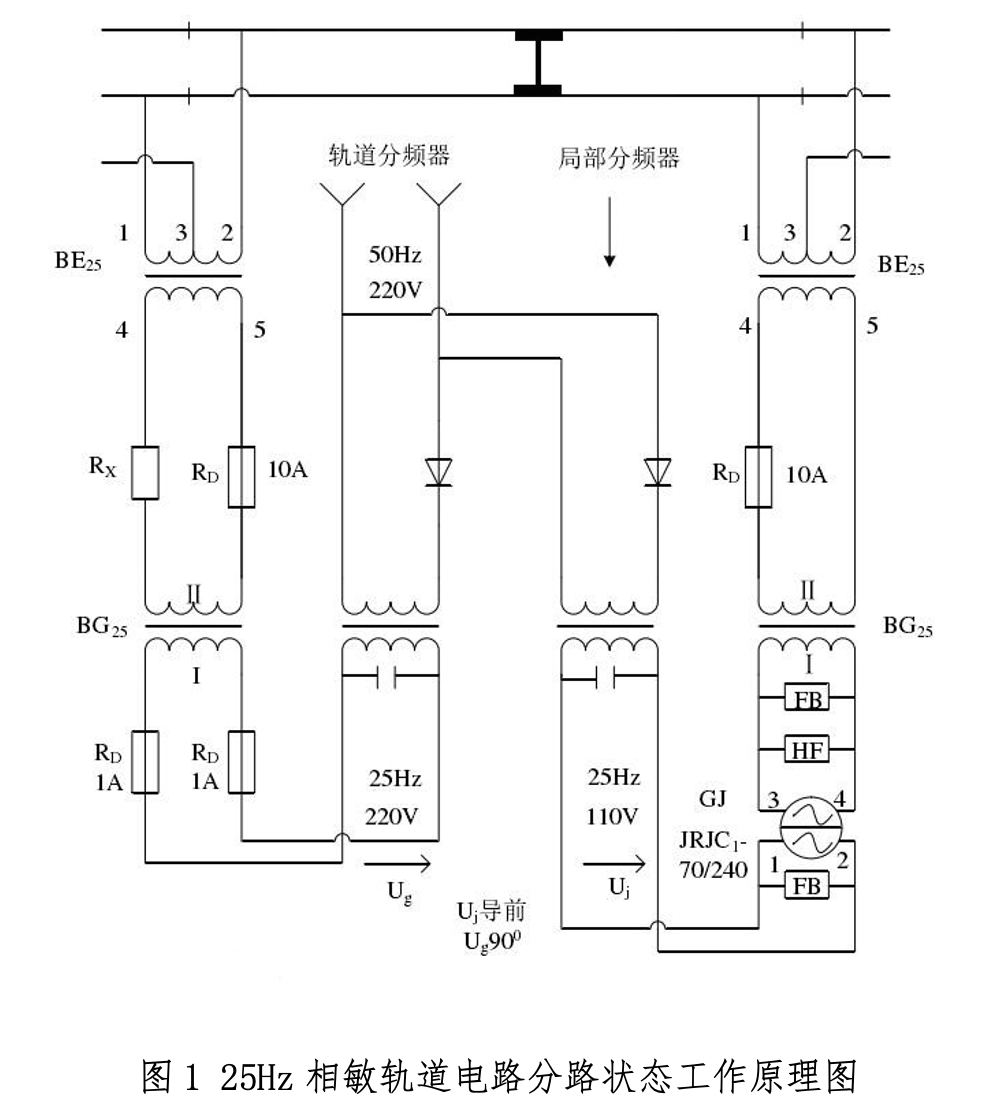
25Hz相敏轨道电路常见故障主要有三类:道砟电阻过低(0100)、绝缘节破损(0010)和引接线接触不良(0001)。每种故障的轨道继电器电压具有不同的变化特性。基于已有数据(6000组数据),设计并实现25Hz相敏轨道电路常见故障的智能诊断算法。
# 智能诊断方法原理介绍
# 整体思路
此次案例是一个有监督学习过程,通过使用LightGBM 模型构建分类树模型,完成数据分类。
# LightGBM 简介
GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT不仅在工业界应用广泛,通常被用于多分类、点击率预测、搜索排序等任务;在各种数据挖掘竞赛中也是致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。而LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。
# 工具准备
环境:
- 操作系统:Ubuntu 20.04.3 LTS (GNU/Linux 5.8.0-44-generic x86_64)
- Python:Python 3.8.5
- GCC:7.3.0
工具包:
- pandas
- lightgbm
- sklearn
- matplotlib
# 训练过程
导入必要的库文件
import pandas as pd import lightgbm as lgb import matplotlib.pyplot as plt from lightgbm import LGBMClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report,accuracy_score使用 pandas 读入数据
data = pd.read_excel('/home/anrunlu/gddata.xlsx')查看一下读入的数据
print(data) # 结果显示 data 是一个 6000×34 的矩阵
查看一下数据的纬度特征
print(data.shape) # 结果显示 (6000,34)原始数据说明:
- 前 30 列
[0:29]为特征列 - 末尾 4 列
[30:33]为标签列,每一行的这四列数有且仅有一位会被标记为1,代表着对应的标签。
- 前 30 列
为了使标签数据更容易被模型处理,需要对标签数据进行一下简单的编码
# 标签编码 data_labels = [] for i in range(0,len(data)): for label in range(0,4): # 把四位数字转化成 0 1 2 3 这样的一位的数字 if data.loc[i][label+30] == 1: data_labels.append(label) break得到编码完成后的数据标签后,把元素数据的末尾 4 列删除
# 删除原始数据的标签 del data[30] del data[31] del data[32] del data[33] # 再次查看数据维度特征 print(data.shape) # 结果显示 (6000, 30)随机划分训练数据和测试数据
# 随机划分训练数据和测试数据 train_X, test_X, train_Y, test_Y = train_test_split(data, data_labels, test_size=0.5, random_state=42,shuffle=True) # 简单查看一下划分结果 print(f"训练数据大小:{len(train_X)}\n测试数据大小:{len(test_X)}") 训练数据大小:3000 测试数据大小:3000设置模型参数
# 设置参数 clf = LGBMClassifier( n_estimators=30, # 拟合的树的棵树,相当于训练轮数 learning_rate=0.08, # 学习率 num_leaves=2**5, # 树的最大叶子数 colsample_bytree=.65, # 训练特征采样率 列 max_depth=5, # 最大树的深度 reg_alpha=.3, # L1正则化系数 reg_lambda=.3, # L2正则化系数 min_split_gain=.01, # 最小分割增益 min_child_weight=2, # 分支结点的最小权重 verbose=-1, # 训练过程是否打印日志信息,-1 代表 )开始训练
# 开始训练 clf.fit(train_X, train_Y)预测
# 预测 predict = clf.predict(test_X)打印结果报告
# 打印结果报告 print(accuracy_score(test_Y, predict)) print(classification_report(test_Y, predict))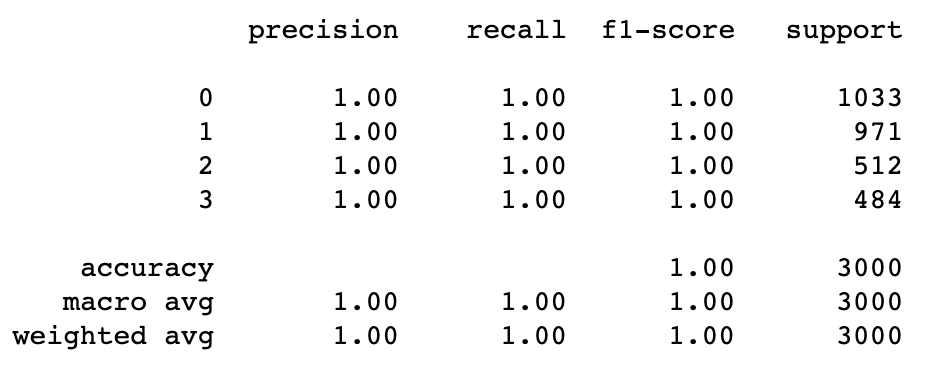
结果显示预测准确率为 100%
# 完整代码
import pandas as pd
import lightgbm as lgb
import matplotlib.pyplot as plt
from lightgbm import LGBMClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,accuracy_score
# 读入数据
data = pd.read_excel('/home/anrunlu/gddata.xlsx')
# 标签编码
data_labels = []
for i in range(0,len(data)):
for label in range(0,4):
if data.loc[i][label+30] == 1:
data_labels.append(label)
break
# 删除原始数据的标签
del data[30]
del data[31]
del data[32]
del data[33]
# 随机划分训练数据和测试数据
train_X, test_X, train_Y, test_Y = train_test_split(data, data_labels,
test_size=0.5, random_state=42,shuffle=True)
# 简单查看一下划分结果
print(f"训练数据大小:{len(train_X)}\n测试数据大小:{len(test_X)}")
# 设置训练参数
clf = LGBMClassifier(
n_estimators=30,
learning_rate=0.08,
num_leaves=2**5,
colsample_bytree=.65,
max_depth=5,
reg_alpha=.3,
reg_lambda=.3,
min_split_gain=.01,
min_child_weight=2,
verbose=-1,
)
# 开始训练
clf.fit(train_X, train_Y)
print('画出特征重要度...')
ax = lgb.plot_importance(clf, max_num_features=10)
plt.show()
# 预测
predict = clf.predict(test_X)
# 打印结果报告
print(classification_report(test_Y, predict))
# 结果与分析
# 结果
结果报告显示,模型的分类准确度为 100%,3000条测试数据全部预测正确。
precision recall f1-score support
0 1.00 1.00 1.00 1033
1 1.00 1.00 1.00 971
2 1.00 1.00 1.00 512
3 1.00 1.00 1.00 484
accuracy 1.00 3000
macro avg 1.00 1.00 1.00 3000
weighted avg 1.00 1.00 1.00 3000
# 分析
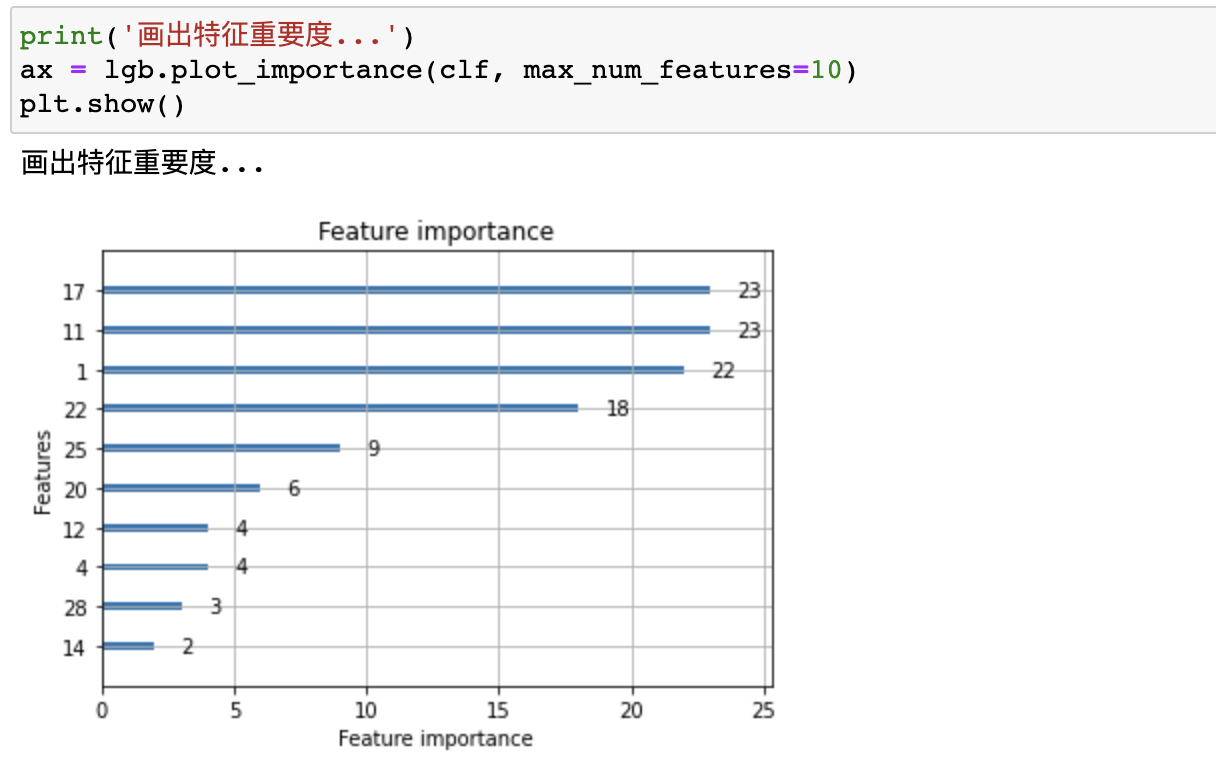
上图显示了10个最突出的数据特征,纵坐标数字代表他在原始数据中的列数(列标从0开始)。
通过特征重要度分析发现,某几个数据特征非常的明显,这是之所以算法效率和准确度高的一个重要原因。
# 总结
首先,这次试验,一开始我对于30个数据特征只用了3000条训练数据得到 100% 准确率的结果有些吃惊,一度以为自己做错了,又尝试了几遍,也尝试用其他模型训练过,最终得到的结果都很一致,基本上都在 99%-100%。最后通过特征分析发现,确实是这批数据某几个特征太明显了,权重最大的前四个特征几乎完全决定了实例的分类结果。
其次,我觉得对于复杂的问题应该积极去探索去学习高效的解决方法,不能局限于脑子里现有的知识。这次实验一开始我尝试过 BP 网络、KNN 等分算法,训练时间相对较长而且得到的结果也不是十分的令我满意,因此我开始查找用树模型做分类的算法,于是就发现了LightGBM,然后成功地使用了 LightGBM 框架下的 LGBMClassifier模型在代价相对低很多(3000条数据,个人计算机10几秒即可训练完成)的情况下解决了问题。
最后,感谢这们课程,感谢老师带领我走进人工智能的大门,让我在知识的海洋遨游。
吾生也有涯,而知也无涯。加油!!!