毕业实训日记
# 2 月 13 日
# 课上
大数据、人工智能、云计算概念
VMware 虚拟机安装
虚拟机安装 Centos 系统
配置虚拟机网络
NAT 模式
Centos 配置
配置网卡
vim /etc/sysconfig/network-scripts/ifcfg-ens33 # 网卡设备名称不一定是 ens33 ··· BOOTPROTO="static" # 静态IP ONBOOT="yes" # 在系统引导时是否激活此设备 IPADDR="192.168.1.101" # ip 地址 NETMASK="255.255.255.0" # 子网掩码 GATEWAY="192.168.1.1" # 网关 DNS2=192.168.1.1 # DNS1:第一个DNS服务器指向 DNS1=8.8.8.8 # DNS2:第二个DNS服务器指向 ···重启网络服务
systemctl restart network
# 自学
# 2 月 14 日
# 课上
Linux 基本命令/程序使用
cd ls
mkdir touch
rm
echo cat
cp mv
vi
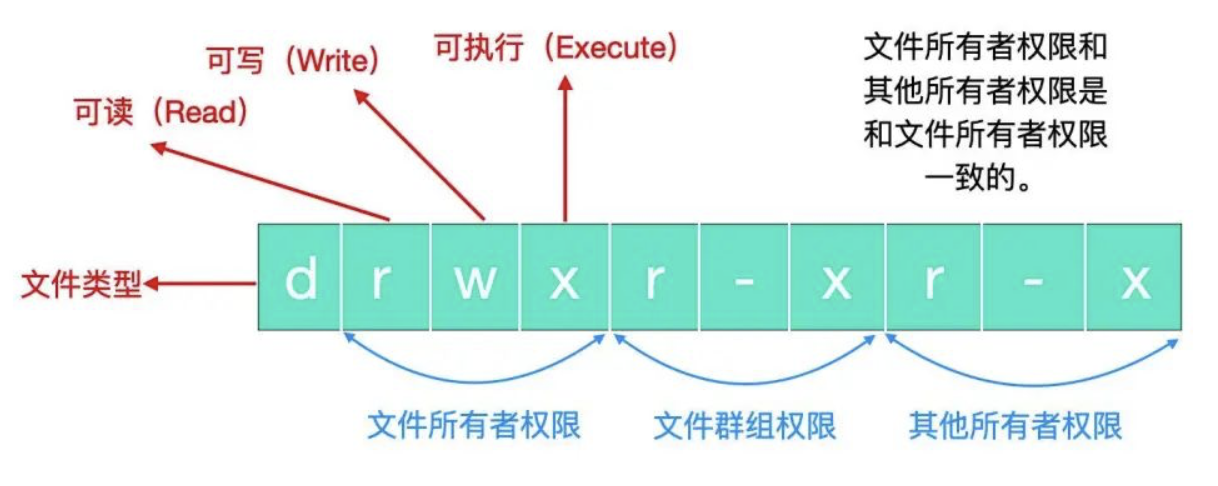
Linux 文件权限
Linux 命令/程序
chmod
使用数字改变文件权限(常用)
Linux 文件基本权限有 9 种,分别是 owner/group/others 三种身份加自己的 read/write/execute 权限,这九个权限三个为一组,我们可以使用数字表示各个权限。
rwx 就表示 4 + 2 + 1 = 7,我们最常见的
chmod 777它就表示赋予所有的权限。使用符号改变文件权限
九种文件权限分别对应着:(1) user (2) group (3) others,所以我们可以借由 u,g,o 来代表三种身份的权限。除此之外,a 代表 all 即全部的身份。
比给文件设置 -rwxr-xr-x 权限,那么我们所使用的命令应该是
chmod u=rwx,go=rx .filename # u:user go:group&others给所有人增加写入权限
chmod a+w .filename # a:all给所有人去掉写入权限
chmod a-w .filename三种指令,分别是 =、+、- 号,= 号表示赋值指定权限
# 自学
docker 搭建完全分布式 hadoop 环境,三个容器
创建目录并准备 JDK 和 hadoop

编写 Dockerfile
FROM centos:centos7 # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no RUN yum install -y openssh-server sudo RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config #安装openssh-clients RUN yum install -y openssh-clients # 添加测试用户root,密码root,并且将此用户添加到sudoers里 RUN echo "root:root" | chpasswd RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key # 启动sshd服务并且暴露22端口 RUN mkdir /var/run/sshd EXPOSE 22 CMD ["/usr/sbin/sshd", "-D"] ADD jdk-8u361-linux-x64.tar.gz /usr/local/ RUN mv /usr/local/jdk1.8.0_361 /usr/local/jdk1.8 ENV JAVA_HOME /usr/local/jdk1.8 ENV PATH $JAVA_HOME/bin:$PATH ADD hadoop-3.3.1.tar.gz /usr/local RUN mv /usr/local/hadoop-3.3.1 /usr/local/hadoop ENV HADOOP_HOME /usr/local/hadoop ENV PATH $HADOOP_HOME/bin:$PATH构建镜像
docker build -t centos-hadoop ./ # docker build -t ImageName:TagName dirHadoop 网络结构
hadoop0:192.168.1.2
hadoop1:192.168.1.3
hadoop2:192.168.1.4
创建子网
docker network create --subnet=192.168.1.0/24 hadoopnet # 网络名称为 hadoopnet 的子网启动容器
docker run -itd --name hadoop0 --net hadoopnet --ip 192.168.1.2 -p 8088:8088 -p 9870:9870 centos-hadoop # hadoop0对外开放端口8088 docker run -itd --name hadoop1 --net hadoopnet --ip 192.168.1.3 centos-hadoop docker run -itd --name hadoop2 --net hadoopnet --ip 192.168.1.4 centos-hadoop
对主节点 hadoop0 进行操作
进入容器
docker exec -it hadoop0 /bin/bash # 进入容器并进行交互通过 ping 命令检查是否已有网络映射关系
ping hadoop0 ping hadoop1 ping hadoop2配置 ssh 免密登录
ssh-keygen #剩下的一路回车即可 # 以下3条都不能省,请根据提示输入yes以及主机密码,开头我们设置的是root/root ssh-copy-id hadoop0 ssh-copy-id hadoop1 ssh-copy-id hadoop2hadoop 的相关配置
进入/usr/local/hadoop/etc/hadoop 目录,涉及的配置文件有:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
# hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.8 # 修改JAVA_HOME# core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop0:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration># hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration># yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>hadoop0</value> </property> </configuration># mapred-site.xml <configuration> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> </configuration>格式化 hadoop
为什么要格式化:
- Hadoop 生态中的文件系统 HDFS 类似一块磁盘,初次使用硬盘需要格式化,让存储空间明白该按什么方式组织存储数据。
- 格式化 NameNode 会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到以往数据。
如何格式化:
格式化 NameNode 前,先关闭掉 NameNode 节点和 DataNode 节点,然后一定要删除 hadoop 目录下的 data 文件夹和 log 日志文件夹。最后再进行格式化。
hadoop namenode -format在容器中进入
/usr/local/hadoop目录执行命令
bin/hdfs namenode -format
修改 workers 文件
vim /usr/local/hadoop/etc/hadoop/workers内容为下
hadoop1 hadoop2拷贝至其他两个节点
scp -rq /usr/local/hadoop/etc hadoop1:/usr/local/hadoop scp -rq /usr/local/hadoop/etc hadoop2:/usr/local/hadoop添加变量
cd /usr/local/hadoop/sbin## 在start-yarn.sh、stop-yarn.sh顶部添加 YARN_RESOURCEMANAGER_USER=root HDFS_DATANODE_SECURE_USER=yarn YARN_NODEMANAGER_USER=root## 在start-dfs.sh、stop-dfs.sh顶部添加 HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root启动 hadoop 分布式集群服务
sbin/start-all.sh若需要中止 hadoop 分布式集群服务
sbin/stop-all.sh验证完全分布式集群是否正常
主节点
[root@862fe05b10de /]# jps 932 SecondaryNameNode 1477 ResourceManager 569 NameNode 5835 Jps从节点
[root@5e43ab21d984 /]# jps 67 DataNode 1236 Jps 238 NodeManager运行示例程序
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10
成功
# 2 月 15 日
# 课上
搭建集群
公共域名解析服务器
114.114.114.114 三大运营商提供,国内首选
8.8.8.8 Google 公司提供,国外首选
hadoop
HDFS(分布式文件系统)
NameNode
NameNode 是 HDFS 的核心 NameNode 也称为 Master NameNode 存储 HDFS 的元数据:文件系统中所有的目录树,并跟踪整个集群的文件 NameNode 不存储实际数据 NameNode 知道 HDFS 中任何给定文件的块列表及其位置,使用此信息 NameNode 知道如何从块中构建文件 NameNode 不持久化存储每个文件中各个块所在的节点信息,这些信息会会在系统启动时从块中数据节点重建 NameNode 关闭,集群将无法访问 NameNode 所在的机器通常配置大量内存
DataNode
DataNode 负责将实际数据存储在 HDFS 中 DataNode 也称为 Slave NameNode 和 DataNode 会保持不断通信 DataNode 启动时,会将自己发布到 NameNode 并汇报自己负责的块列表 某个 DataNode 关闭不会影响集群的正常使用 DataNode 每 3 秒向 NameNode 发送心跳,若 NameNode 长时间(10 分钟)没有接受到 DataNode 发送的心跳则认为该节点不可用,会将该节点的数据复制到其他节点,并且永远不再使用该节点(退出集群后再次上线可以恢复) DataNode 所在的机器通常配置大量磁盘空间
MapReduce(分布式计算框架)
Yarn(资源调度)
# 自学
- Linux 修改主机名称
hostnamectl set-hostname <newhostname>
VMware 克隆虚拟机
创建完整克隆
克隆后的机器配置一下 ip,删除网卡配置里面的 uuid,重启网络服务
systemctl restart network
ssh 免密登录
生成秘钥对
ssh-keygen将本机的公钥复制到远程机器的 authorized_keys 文件中
ssh-copy-idhost
Linux 命令行帮助文档命令语法公式格式
参数
< >表示参数选项
-o或--option短选项
-可以以堆叠,意思三个选项-a -b -c可以写成-abc,并且他们作用等价短选项可以在
零~多个空格后指定参数,并且他们作用等价。-a file等价于-afile等价于-a(多个空格)file长选项可以在
一个或多个空格或等于符号=后指定参数:如--input=ARG等价于--input ARG等价于--input(多个空格)ARG命令
不遵循
<arguments>或--options规则的其他单词都被解释为命令或子命令[可选元素]元素是指选项,参数,命令用方括号
[]括起来的元素被标记为可选的,意思是:可以有该元素也可以没有该元素。元素是否包含在相同或不同的括号内并不重要,它们完全等价。例如:my_program [command --option <argument>] my_program [command] [--option] [<argument>] 正确案例: my_program [command --option <argument>]的所有可能性: 第一种可能性:my_program command --option argument 第二种可能性:my_program 第三种可能性:my_program command 第四种可能性:my_program --option 第五种可能性:my_program argument 第六种可能性:my_program --option argument 第七种可能性:my_program command argument 第八种可能性:my_program command --option小括号
(必选元素)默认情况下,所有元素都是必需的,如果不包括在括号
[]中。然而,有时有必要根据需要显式地使用括号()标记元素。例如,当您需要对互斥元素进行分组时(参见下一节):my_program (--either-this <and-that> | <or-this>)另一个用例是,当您需要指定如果有一个元素存在,那么就需要另一个元素,您可以这样实现:
my_program [(<one-argument> <another-argument>)]在这种情况下,有效的程序调用可以没有参数,也可以有两个参数。
元素
|其他互斥的元素可以通过竖杠
|进行分离,如下:my_program go (--up | --down | --left | --right)在需要互斥的情况下,使用括号
()对元素进行分组。在不需要互斥的情况下,使用括号[]将元素分组:my_program go [--up | --down | --left | --right]注意,指定几个模式的工作原理与竖杠
|完全相同,即:my_program run [--fast] my_program jump [--high]与下面的命令等价
my_program (run [--fast] | jump [--high])...表示重复的元素,指定左边的参数(或一组参数)可以重复一次或多次使用省略号
...指定左边的参数(或一组参数)可以重复一次或多次:my_program open <file>... my_program move (<from> <to>)..
示例
Naval Fate.
Usage:
naval_fate ship new <name>...
naval_fate ship <name> move <x> <y> [--speed=<kn>]
naval_fate ship shoot <x> <y>
naval_fate mine (set|remove) <x> <y> [--moored|--drifting]
naval_fate -h | --help
naval_fate --version
Options:
-h --help Show this screen.
--version Show version.
--speed=<kn> Speed in knots [default: 10].
--moored Moored (anchored) mine.
--drifting Drifting mine.
海军的命运.
用法:
海军的命运 开船 新的<船的名字>...
海军的命运 开船 <船的名字> 移动到 <坐标轴x> <坐标轴y> [--速度=<海里每小时>]
海军的命运 开船 开炮射击 <坐标轴x> <坐标轴y>
海军的命运 水雷 (埋雷|清雷) <坐标轴x> <坐标轴y> [--停泊|--漂泊]
海军的命运 -h | --help
海军的命运 --版本
选项:
-h --help 展示这个帮助页面
--版本 战术“海军的命运”的版本号.
--速度=<海里每小时> 海里每小时 [默认值: 10].
--停泊 停泊船(抛锚固定好船)时,对水雷进行操作.
--漂泊 船在漂泊(开动)时,对水雷进行操作.
# 2 月 16 日
# 课上
配置 hadoop 完全分布式环境
# 将 java 添加到环境变量中
vim /etc/profileexport JAVA_HOME=/your/java/path export PATH=$PATH:$JAVA_HOME/bin
刷新配置
source /etc/profile
安装 hadoop2.4.1
先上传 hadoop 的安装包到服务器上去 /home/hadoop/
注意:hadoop2.x 的配置文件 $HADOOP_HOME/etc/hadoop
# 配置 hadoop
- 修改 hadoop-env.sh 中的 JAVA_HOME 和
export JAVA_HOME=/your/java/path
core-site.xml
<!-- 指定HADOOP所使用的文件系统 schema(URI),HDFS的老大(NameNode)的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/your/hadoop/path/tmp</value> </property>
hdfs-site.xml
<!-- 指定 HDFS 副本的数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hadoop02:50090</value> </property>
mapred-site.xml
mv mapred-site.xml.template mapred-site.xmlvim mapred-site.xml<!-- 指定 mr 运行在 yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <!-- reducer 获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
编辑 slaves
hadoop01 hadoop02 hadoop03
# 将 hadoop 指令目录加入到系统环境变量
vim /etc/profile
# 追加
export HADOOP_HOME=/your/hadoop/path
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# 格式化 namenode
hdfs namenode -format
# 启动 hadoop
先启动 HDFS
start-dfs.sh
再启动 YARN
start-yarn.sh
# 验证是否启动成功,在三台主机分别使用 jps 命令验证
主机 1
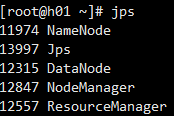
主机 2

主机 3
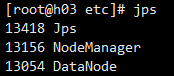
# 测试示例程序
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-{version}.jar pi 10 10
成功
# 关闭 centos 防火墙
systemctl disable firewalld
http://hadoop01:50070 (HDFS 管理界面)
http://hadoop01:8088 (MR 管理界面)